
Do you know 37,291 companies use Apache Hive?

Yes, Apache Hive is one of the most popular data warehouse components of the Big Data and Data Science landscape and it is an immensely useful tool in distributed processing of data.
It’s mainly used to complement the Hadoop file system with its interface.
In this article we will look into the following
- What Exactly is Apache Hive?
- Apache Hive’s Origin
- Who uses Apache Hive?
- Why was Hive Developed
- Is Hive the same as SQL?
- Is Hive an ETL tool?
- Is Hive a Database?
- Is Hive a programming language?
- Apache Hive vs Hadoop
- Can Hive run without Hadoop?
- Apache Hive vs Apache Spark
- Features of Hive
- When Should I Use Apache Hive?
- When Should I Not Use Apache Hive?
- What is Apache Hive metastore?
- What is a Hive Managed Table?
- What is a Hive External Table?
- Difference between Hive Managed Table and External Table
- Apache Hive Commands
What Exactly is Apache Hive?
Apache hive is an
- open-source,
- distributed data warehousing software that is used to read, write, and manage large datasets residing in distributed storage using SQL like queries.
The query syntax used in Hive is called HQL (Hive query language), which has the syntax similar to SQL.

Before looking into details on when you should use Hive, let’s take a quick look at how it all began, why it was developed in the first place, how it is different from SQL and some of the features of the Hive.
Having knowledge on these will help you to understand better on when should you use Hive
Apache Hive’s Origin
Hive was originally developed by Facebook on October 1, 2010 and is now maintained as Apache Hive by Apache software foundation.

Who uses Apache Hive?
- Netflix - a US based media and digital streaming company,
- Amazon - a multinational technology company,
- CVS Health - an American healthcare company,
- Walmart - an American multinational retail corporation ,
- T-mobile - a multinational telecommunication company,
- AT&T - which is also a multinational telecommunication company are some of the companies around the world who are using Apache Hive.
Why was Hive Developed
The Hadoop ecosystem is not just scalable but also cost effective when it comes to processing large volumes of data. When hadoop was prominent between 2006 and 2010, it was a fairly new framework that packs a lot of punch.
Problem with Hadoop : However, organizations with traditional data warehouses were based on SQL with users and developers that rely on SQL queries for extracting data. It made getting used to the Hadoop ecosystem an uphill task. And that is exactly why hive was developed.

Hive provides SQL intellect, so that users can write SQL-like queries called HQL or hive query language to extract the data from Hadoop.
These SQL-like queries will be converted into map reduce jobs by the Hive component and that is how it talks to the Hadoop ecosystem, HDFS file system, or any other distributed storage systems.
Is Hive the same as SQL?
You may have a confusion as to how the hive is different from the traditional SQL language. Let’s take a quick look on how Hive differs from the SQL

Is Hive an ETL tool?
If you aren’t sure what ETL process is, ETL is an Extract, Transform, and Load process. This means it is a process where
- Extracting data from one or more data sources like Kafka, cloud storage services like s3, Azure Storage or Google cloud storage happens first,
- Transforming data like filtering the data, joining data with other datasets (or) aggregation step (or) any modification to the data happens second and then finally
- Loading data (loading the transformed data into the target tables) are done.
Below chart should explain the ETL process clearly.
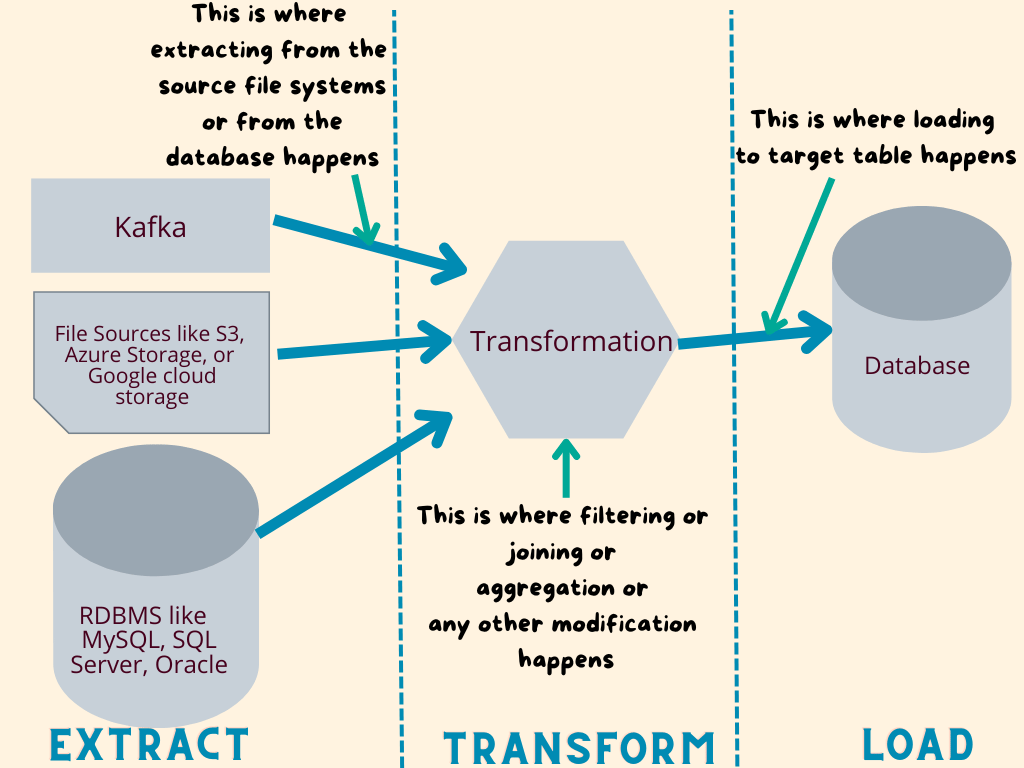
There are various tools specifically built for the ETL process. Even though Hive isn’t specifically built for the ETL process, it still can help with the ETL process. For e.g. after extracting the data from source, it can be loaded to intermediate hive tables, transformed and then loaded to final target hive tables.
Is Hive a Database?
Hive doesn’t store the data in itself. So , No, Hive is not a database. It is rather built as a data warehousing software that can help you to create databases and tables in hive.
It acts as an interface that overlays over the data, and enables users to query the data using SQL like language.
Is Hive a programming language?
Hive is not a programming language. It is more a query language, that is similar to SQL.
It provides SQL like syntax. So you can start running queries like “SELECT * FROM <TABLE-NAME>” and that will help you to retrieve the data from the hive tables.
It is not a programming language, like Python, Scala, or Java.
Apache Hive vs Hadoop
Hadoop is a framework that helps you to manage and query the data in distributed storage like HDFS (Hadoop Distributed File System).
In Hadoop, you have to write programs in Map-Reduce which is a programming paradigm. You need to use languages like Java or Python to write code in map-reduce framework to use the Hadoop framework, which is relatively more complex than writing SQL queries.
However Hive provides a SQL type language that helps you to submit queries using simple SQL syntax, which gets internally translated to map-reduce programs and gets submitted to distributed storage systems to retrieve and manage the data.
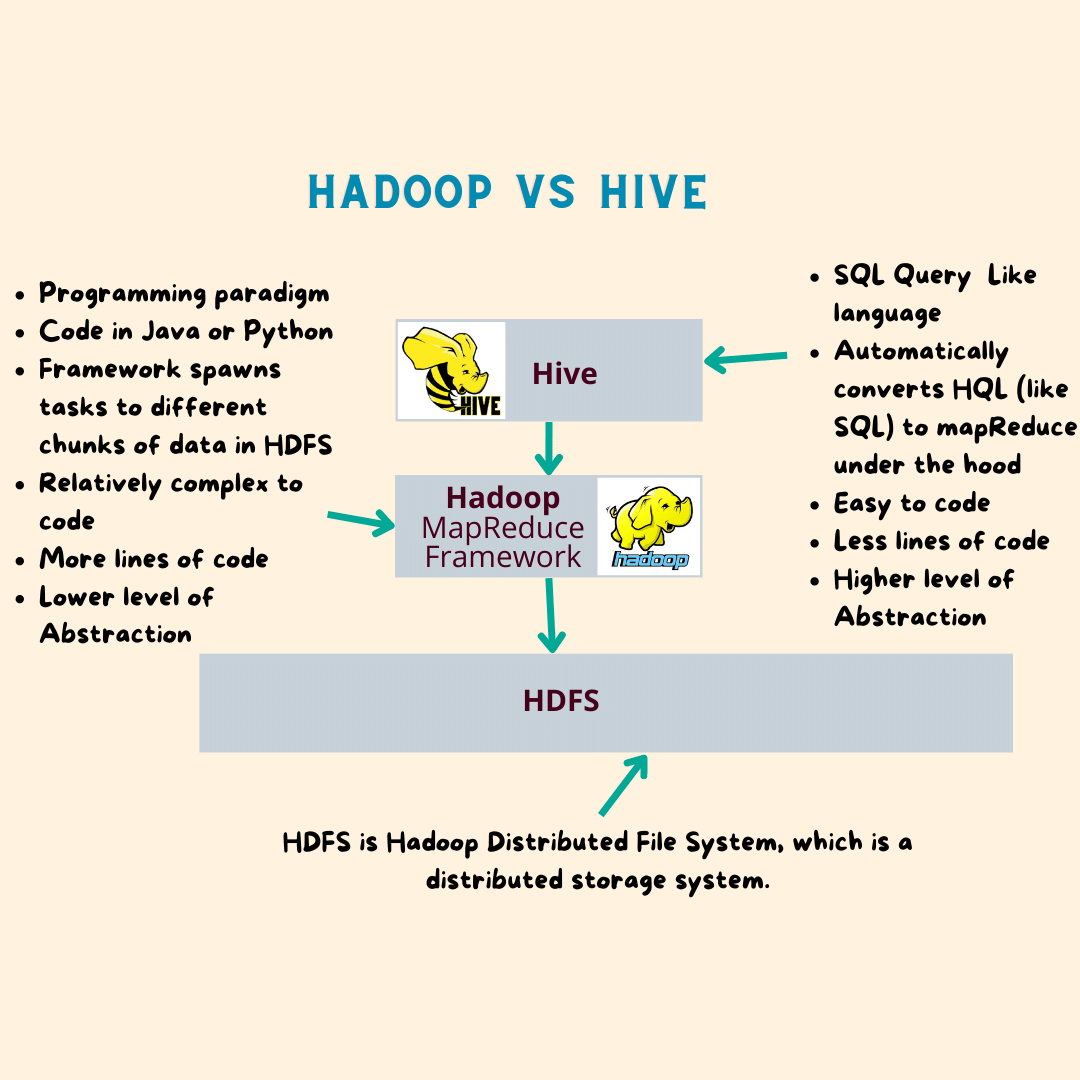
So Hive uses the same framework as hadoop under the hood, however the outer interface let’s Hive users submit as HQL queries
You can think of hive as a layer on top of Hadoop that lets users submit SQL type queries, instead of writing complex map-reduce programs. Hive takes care of translating the queries to map-reduce under the hood.
Can Hive run without Hadoop?
No, Hive needs Hadoop to run. This is because hive is an infrastructure that is built on top of the hadoop. So under the hood Hive still uses Hadoop to process and manage the distributed data.
Apache Hive vs Apache Spark
Hive and Spark use an entirely different framework and they are different processing engines.
For e.g. Hive under the hood uses Hadoop framework which manages and processes the data as map-reduce jobs.
However spark is a different framework that uses an in-memory processing engine, which means it doesn’t store the intermediate processed data in local disk, but rather keeps them in memory. This facilitates spark framework to process the data much faster than hadoop or hive.
If you ask should we choose hive or spark, the answer is usually both.
You should use Apache Spark for faster distributed processing of the data. However you still need to use Apache Hive to store the metastore related information and also to create & manage the tables.
Apache Spark is more preferable for the actual processing of the data and reading and storing of the data. This is because Apache Spark performs everything in-memory and it is much faster than Hive’s way of processing the data.

Features of Hive
- It supports different file formats like sequence file, text file, avro file format, ORC file, RC file
- Metadata gets stored in RDBMS like derby database
- Hive provides lot of compression techniques, queries on the compressed data such as SNAPPY compression, gzip compression
- Users can write SQL like queries that hive converts into mapreduce or “Tez” or spark jobs to query against hadoop datasets
- Users can plugin mapreduce scripts into the hive queries using UDF user defined functions
- Specialized joins are available that help to improve the query performance

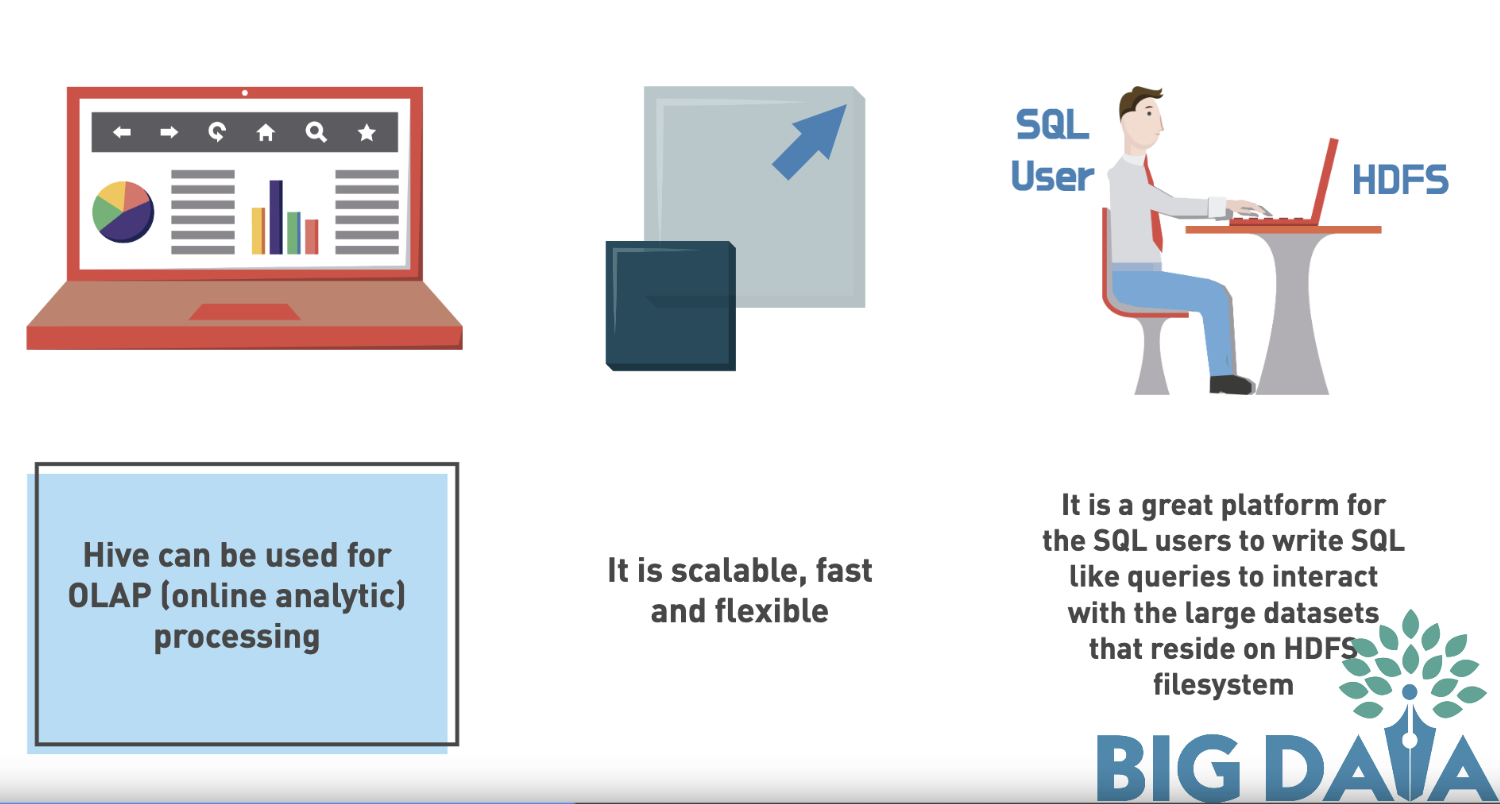
When Should I Use Apache Hive?
- Hive can be used for OLAP (online analytic) processing
- It is scalable, fast and flexible
- It is a great platform for the SQL users to write SQL like queries to interact with the large datasets that reside on HDFS filesystem or other distributed storage systems
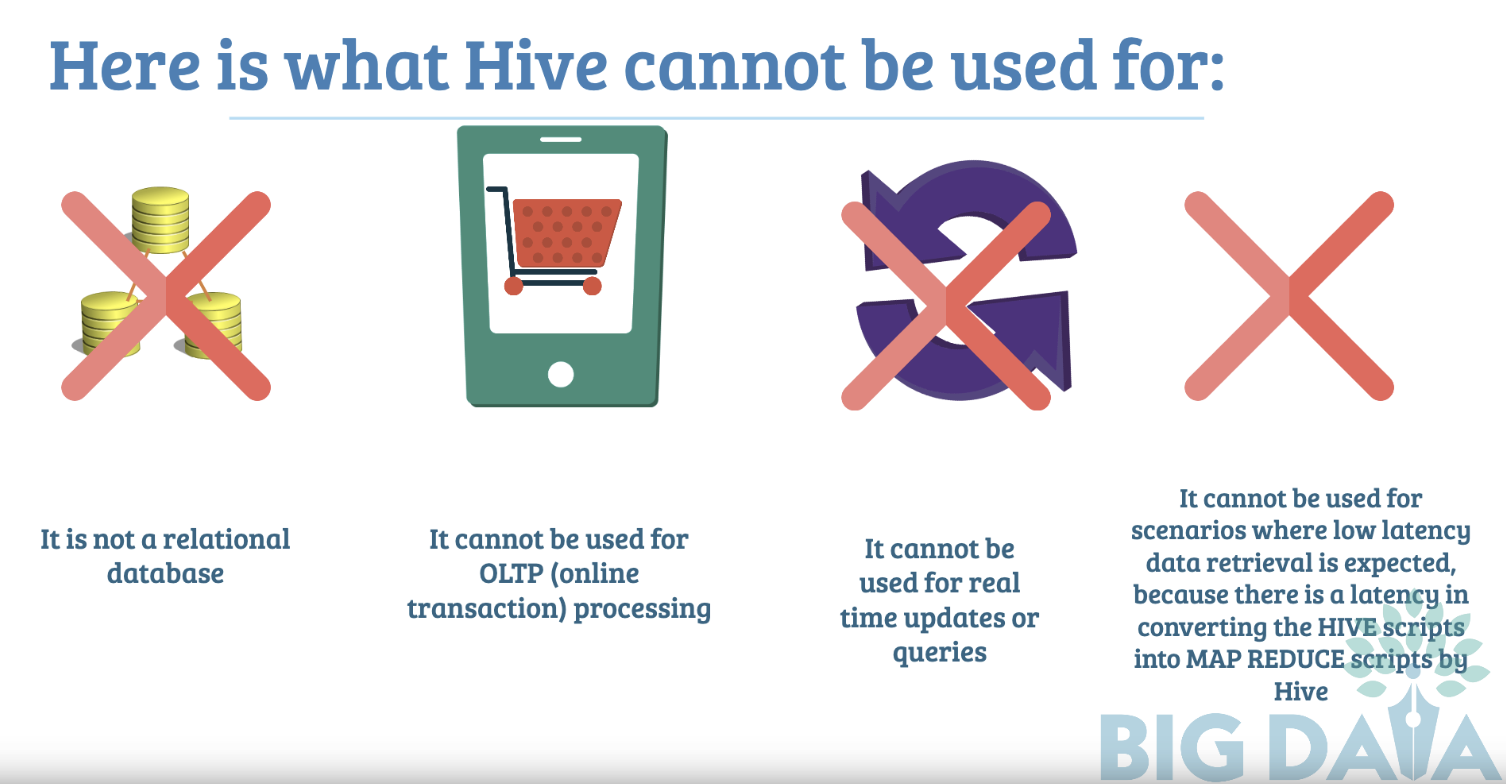
When Should I Not Use Apache Hive?
- It is not a relational database
- It cannot be used for OLTP (online transaction) processing
- It cannot be used for real time updates or queries
- It cannot be used for scenarios where low latency data retrieval is expected, because there is a latency in converting the HIVE scripts into MAP REDUCE scripts by Hive
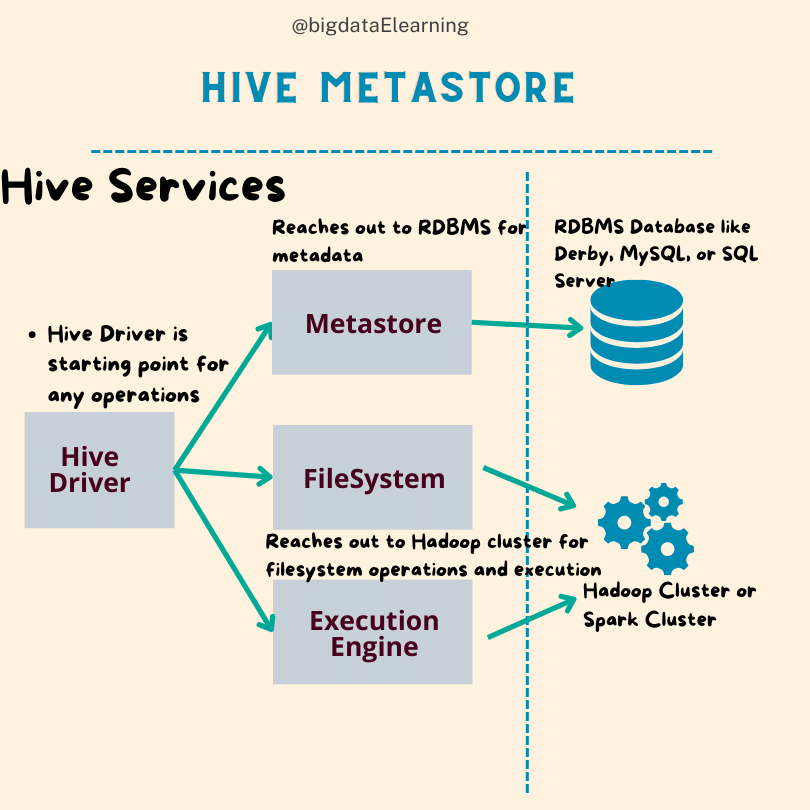
What is Apache Hive metastore?
Apache Hive metastore is the one that stores the metadata of the hive tables.
Metadata scary term? Don’t worry.
Metadata is nothing but the data about data.
For e.g. it contains the schema, location of the table, column names, data types, partition information, file format, etc..
"The Apache Hive Metastore is nothing but the central repository where the metadata of the tables are stored."
Hive Metastore is normally a relational database like Derby, MySQL, or SQL server. Hive by default comes with a derby database. We have an option to configure it to point to MySQL or other relational databases. According to the configuration the metadata information of the hive tables are stored in one of these databases.
When you perform “describe extended <table-name>” to find more details on a table, then internally hive fetches the metadata information from the metastore, which is nothing but a relational database.
Also when the hive server tries to serve your query request, it fetches the actual data from the distributed storage. However when it needs to quickly fetch the metadata information, it goes and finds it from the relational database
What is a Hive Managed Table?
A managed table can be created using the “CREATE TABLE <TABLENAME>” statement.
The schema of the hive tables will be stored in an RDBMS database like DERBY database or MySQL database, based on how it is configured. Some information like column names, the data types, location of the table will also be stored in the RDBMS database.
The reason for storing this information in RDBMS is that they are required to have low latency by the compiler. If you had performed a “describe <tablename>” command in the hive, you would have seen the table schema immediately appearing after typing the command and hitting enter key.
However when you query the tables to retrieve the actual data, there is a small latency due to the data being stored in HDFS and there being a small delay in converting your hive queries into mapreduce jobs.
"In Hive managed tables, data usually gets stored in a preconfigured location."
What is a Hive External Table?
An external table can be created using the “CREATE EXTERNAL TABLE <TABLENAME>” statement. Notice the “External” keyword.
"In the Hive external table, data usually gets stored in the location that is specified in the Apache Hive DDL command."
Difference between Hive Managed Table and External Table
"When you drop an external table, it removes only the metadata. The underlying HDFS directory will remain intact."
The purpose of this is to leave it to the users to manage the HDFS files and directories in an external table.
"On the other hand when you drop a managed table, the data and metadata are removed."
This means underlying HDFS directories/data will also be deleted along with the metadata. Here both the metadata and the underlying HDFS directories are taken care and thus the name managed
However for external tables, only the metadata information is permanently deleted and the actual data remains intact in the HDFS directories. So in the case of an external table, if the table was deleted accidentally, then the table can be re-created by using the same schema and specifying the same location for the HDFS data directory.
If deleting the external table was the intention, then after deleting the table using the drop statement, you may also delete the underlying HDFS data directory by issuing the HDFS dfs -rm command.

Apache Hive Commands
We will look into some of the commonly used Apache Hive Commands
How to create a basic Hive table?
The syntax for creating managed table is as highlighted:
CREATE TABLE <TABLE_NAME> (col1 datatype, col2 data type…, coln datatype) row format delimited fields terminated by ' ' STORED as textfile;
The syntax for creating an external table is as below
CREATE EXTERNAL TABLE <TABLE_NAME> (col1 datatype, col2 data type…, coln datatype) row format delimited fields terminated by ' ' STORED as textfile LOCATION <‘location-path’>;
How to insert records into a Hive table?
INSERT statement is used to insert values into a hive table from a local unix file, (or) from a distributed storage system like HDFS file, (or) using the data from another hive table.
For e.g. below command can be used to load data from a local path to overwrite a hive table.
LOAD DATA LOCAL INPATH <'local-filepath'> OVERWRITE INTO TABLE <tablename>;
Below command can be used to insert data from a distributed storage system like HDFS file into a hive table
LOAD DATA INPATH <'hdfs-filepath'> OVERWRITE INTO TABLE <tablename>;
We can also insert some hard coded values into the hive table, by specifying them directly in the query. The below INSERT INTO statement can be used to insert a few values directly into the table by specifying the data directly in the query.
INSERT INTO TABLE <table-name> VALUES ('fred flintstone', 35, 1.28), ('barney rubble', 32, 2.32);
You can use this statement to load data into the table by querying the data from another table.
INSERT OVERWRITE TABLE <tableName1> SELECT * FROM <tableName2>;
How to alter a Hive table?
Here is the syntax to change the table name using ALTER statement
ALTER TABLE <TABLE_NAME> RENAME TO <NEW_TABLENAME>
And the syntax to add columns to the table using ALTER statement is:
ALTER TABLE <TABLE_NAME> ADD COLUMNS (newcol1 datatype, newcol2 datatype);
For replacing or removing the columns using ALTER statement we can use the following syntax
ALTER TABLE <TABLE_NAME> REPLACE COLUMNS (col1 datatype_new, col2 datatype);
How to update a record in a Hive table?
Update statement is used to update certain (or) all rows of the hive table using certain conditions.
Below is the statement used to update certain rows of a table based on certain conditions
UPDATE <tablename> SET column = value WHERE expression;
UPDATE table statement is available from hive 0.14 and above
How to delete a record in a Hive table?
Delete statement is used to delete certain rows from a table based on a condition specified using the WHERE clause.
The syntax is below as highlighted.
DELETE FROM <tablename> [WHERE expression];
Note: DELETE statement is available from hive 0.14.0 version and above
How to drop a Hive table?
The drop table statement is used to drop the table altogether.
The syntax is highlighted here:
DROP TABLE IF EXISTS <TABLENAME>;
How to truncate a Hive table?
Truncate table statement is used to remove only the data from the table. The table structure with the schema remains intact. Truncate removes all the rows from a table or partition. Truncate of the table is done using apache hive commands like below.
TRUNCATE TABLE <TABLENAME>;
Conclusion
In this article we saw that Apache Hive is a
- Open-source
- Distributed data warehousing software
- To read & write huge datasets
- Using SQL like query language
We also saw its origin and uses of Hive.
Then we discovered that Hadoop's complexity is the core reason behind Hive's development. Then we saw how Hive differs from SQL.
Then we illustrated that Hive can be used for ETL process, although Hive is not specifically developed for the ETL.
We also saw that Hive is itself not a Database, but helps to create databases and tables on top of distributed storage systems.
Hive is not a programming language but rather a SQL query language.
We also saw how Hive differs from Hadoop and Spark. One key thing to note is Hive cannot run without Hadoop or distributed storage, because Hive works on top of distributed storage systems.
Then we clarified on when you should use Hive and when you shouldn't use Hive.
We learned that Hive metastore is used to store metadata related information. Then we found the differences between Hive managed table and external table. Finally we saw some of the DDL and DML statements in Hive.
If you haven't started your career in big data yet, now may be the best time to get started. Maybe it's time for you to learn about the field and see if it's what you're looking for.
Why not start your journey now with Big Data eLearning? Enroll in our free online courses, get access to our cheat sheets and strategies, and join our community. We'll be with you every step of the way as you embark on your successful machine learning or data science career.
Now About You.
Are you already a Big Data Engineer?
If you are, leave a comment below with “yes”.
If you are not, leave a comment with no.
If you answered “no”, what is the biggest problem you are facing from getting into a Big Data career?
TELL ME IN THE COMMENTS!
Stay connected with weekly strategy emails!
Join our mailing list & be the first to receive blogs like this to your inbox & much more.
Don't worry, your information will not be shared.


